Attention is all you need (Transformer)
( 이전에 만들어두었던 ppt로 작성되었습니다)
Transformer

많은 PLM들의 백본모델
각 토큰의 hidden state들은 하위 레이어로부터 누적되면서 업데이트 된다.
최종적으로 Transformer의 아웃풋은 시퀀스내부에서 각 토큰들의 문맥적 표현을 담고있을 것이다.
논문에서 제안된 구조

아래부터는 단계별로 설명입니다.
Embedding & positional Encoding

문장의 sparse represetion을 시작으로 word vertor로 매핑시킨다.
중간에 임베딩 차원의 제곱근으로 나누어 스케일링을 진행하고, 위치 정보는 삼각함수를 이용하여 적절히 첨가한다
이렇게 해서 모델에 들어갈 Embedding matrix가 만들어진다
dot product attention
유사도 연산이 들어간 것이 핵심입니다.

이미지 설명
1. data에 대해서 learnable parameter query, key, value와 연관있는 가중치 행렬들을 각각 곱하여 query, key ,value 를 만들어냅니다
2. Query와 Key에 대하여 dot-product 연산을 통해 𝑞𝑖와 𝑘𝑗 간의 similarity들을 계산합니다.
3. Similarity 에 대해서 scaling 해주고,
softmax 함수를 거쳐 각 query에 대한 key들의 similarity score distribution을 계산합니다.
※𝑑𝑘가 큰 경우에 위 행렬의 원소들이 커져서
발생하는 문제를 방지하기 위해 scaling 을 해줍니다.
4. 위에서 구한 distribution을 V와 곱해줍니다.
Distribution에 dropout을 적용해서 결과값들이 좀 더 다양할 수 있도록 만들어 줍니다.
이는 distribution 의 행들을 weight로 하여 V의 각 열에 weighted sum 한 것과 동일합니다
이 연산은 key가 query와 관련이 많을수록 그 key에 대응되는 value에 중요도를 두어서 상대적으로 크게 가중치를 두고 합하는 것입니다.
query와의 similarity가 높은 key가 상대적으로 distribution 의 값이 더 높기 때문에 그 만큼 key에 대응되는 value에 대한 가중치가 높아집니다
5. 앞 과정에서 구해진 attention value와 𝑊_o 를 곱하여 output을 계산합니다.
그리고 Residual Connection 과 LayerNorm 을 적용하여 다음 SubLayer로 보내질 값을 계산합니다..
Multi-head Attention
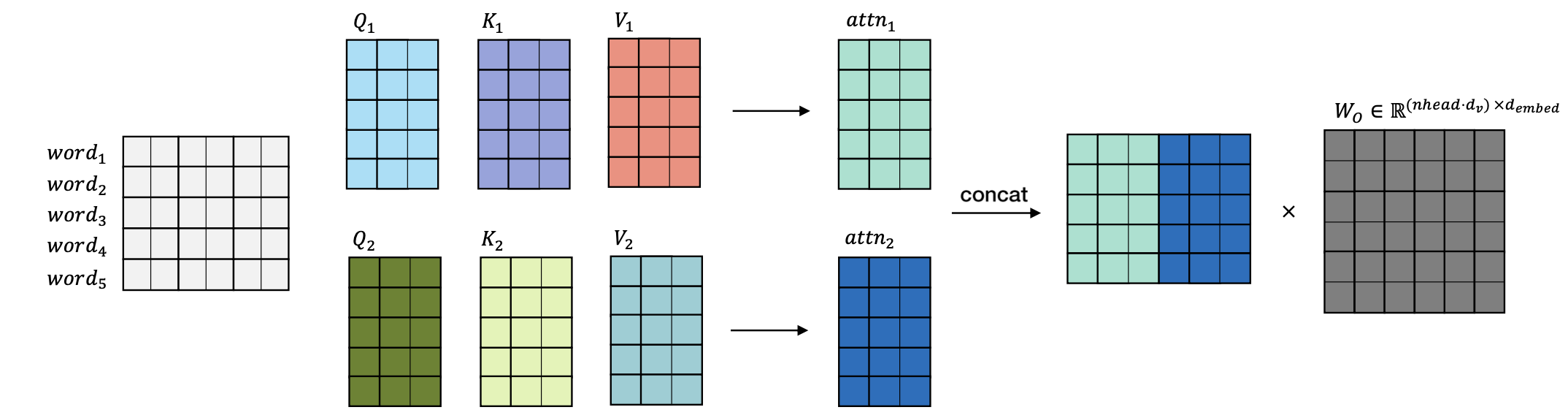
Transformer 모델은 attention 연산을 할 때 각 data에 대해서 한번의 attention 연산이 아닌, 여러 번의 attention을 병렬적으로 나누어 연산하도록 되어있습니다.
• 그래서 𝑑_𝑒𝑚𝑏𝑒𝑑 를 n_head(hyper-parameter) 로 나누어 진행합니다.

이에 대한 직관적인 설명은 ‘attention 을 병렬로 수행하여, 다양한 시점으로 정보를 얻어내겠다’ 는 것입니다
Position-wise Feed Forward Network

attention output에 non-linearity를 추가하여 feature 표현이 보다 풍부해지도록 ReLU actionvation function과 함께 Feed Forward Network를 추가한다고 생각합니다.
Transformer 에 사용되는 3가지 방식의 attention

Encoder Self-Attention
• Encoder 에 입력될 Source text 를 이루고 있는 단어들 간의 모든 관련성을 self-attention을 통해 계산합니다
• 연산과정은 이전 슬라이드의 내용과 동일합니다.
Decoder Masked Self-Attention
• 각 query에 대응되는 key의 이전 key까지만 접근하여 self attention 연산을 진행합니다. ( Look ahead masking )
• Encoder-Decoder 구조에서 Decoder의 Auto-regressive 성질을 보존하려는 목적으로 현재 시점보다 미래에 있는 정보를 참고하지 못하게 하기 위해 softmax 함수의 결과를 0으로 수렴하도록 하는 masking 기법을 적용합니다
• 미래 시점의 단어가 현재 단어의 결정에 영향을 미치지 않기 위해 위와 같은 방식으로 진행합니다.
• 추가적으로, attention value 에서 <pad> token에 해당하는 부분도 masking 해주어 학습에 영향을 끼치지 않도록 합니다.
( padding masking )
Encoder-Decoder Attention
• Decoder Masked Self-Attention 의 output 을 query로 치환하고,
Encoder 의 output 을 key, value 로 치환하여 attention 연산을 수행합니다.
내부 연산의 특성상의 계산 복잡도, 고정된 길이의 학습, Context fragement 등 이 단점으로 지목되었지만, Transformer 이전과 이후를 비교했을 때 큰 발전에 기여한 모델이라고 생각합니다.
또한 그런 단점을 해결하고자 하는 많은 연구들이 진행되고 발전했다고 생각합니다.