pdf : https://aclanthology.org/K19-1057.pdf
cite : Yuze Ji, Youfang Lin, Jianwei Gao, and Huaiyu Wan. 2019. Exploiting the Entity Type Sequence to Benefit Event Detection. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), pages 613–623, Hong Kong, China. Association for Computational Linguistics.
Event Extraction과 Event Detection은 information extraction 분야에서 매우 중요한 task 중 하나로 자리 잡고 있습니다.
Event Extraction은 text data에서 structured event 들을 뽑아내는 작업이며
Event Detection이란 Event Extraction 과정에서 event trigger word를 찾아내고, 찾아낸 단어가 어떤 타입의 event에 해당하는지 분류하는 작업입니다.
우선 저는 Event란 문장이 말하고 있는 하나의 상황을 표현할 수 있는 단어로 이해했으며
Event trigger word란 문장의 Event를 가장 잘 나타낼 수 있는 문장 내부의 단어로 이해했습니다.

본문에 있는 예시인데 여기서 Transport가 Event에 해당하고, dropped는 Event trigger word에 해당합니다
그리고 Soyuz capsule과 astronauts는 entity mention에 해당하고 VEH와 PER는 각각 탈것과 사람을 의미하는 entity type에 해당합니다.
ACE 2005 dataset에서는 다음과 같이 용어들을 정의합니다.
Entity (type) : an object in one of the semantic categories
Entity mention : a reference to an entity (typically, a noun phrase)
Event mention : a phrase or sentence within which an event is described, including the trigger and arguments
Event trigger : the word most clearly expresses the event mention, most often a single verb or noun.
Event argument : an entity mention, temporal expression or value (e.g. Job-Title) that serves as a participant or attribute with a specific role in an event mention.
본문에서는 이전 연구들에선 event detection의 향상을 위해 entity type 정보를 넣었던 연구들은 많았지만
entity type들의 sequential feature를 활용한 연구는 없었다는 점을 언급하면서
다음과 같은 특징을 지닌 event detection approach를 새로 제안했습니다.
1. word sequence와 entity sequence로부터 각각의 sequential feature를 학습
2. trigger-entity interaction learning module를 통해 두 형태의 sequential feature를 조합
언어 표현의 모호성이 event detection을 어려운 task로 만드는 하나의 이슈로 뽑힐 수 있는데
1. 하나의 event type을 표현할 수 있는 단어의 다양성
2. 하나의 event trigger가 여러 event를 표현할 수 있다는 점
같은 부분들이 언어 표현의 모호함에서 야기된다고 이야기할 수 있을 것 같습니다.
reference 논문에서는 banch mark dataset으로 사용되는 ACE 2005 dataset의 경우 57%의 event trigger word가
위와 같은 모호성을 띠고 있다고 이야기합니다.

본문의 예시를 통해 구체적으로 살펴보면, dropped라는 trigger word는 1번 문장에서는 Transport라는 event를 표현하고 2번 문장에서는 Attack이라는 event를 표현합니다.
같은 trigger word가 문장에 따라 다른 event를 표현하는 경우에 해당하는데 이렇게 되는 이유는 trigger word의 의미적 정보가 문장의 context에 의해 결정이 되기 때문입니다.
두 문장의 entity 정보를 각각 고려하면서 dropped의 의미에 대해 생각해보면
1번 문장에서는 VEHICLE과 PERSON에 의해 dropped를 Transport로 분류시키는 것이 자연스럽고
2번 문장의 경우 VEHICLE과 WEAPON이라는 entity 정보가 dropped를 Attack으로 분류시키는 것이 자연스럽습니다.
즉, event detector의 입장에서 trigger word를 event로 분류하는 작업에서는 trigger word만 보는 것이 아니라 entity들의 context 정보도 고려면서 event를 분류하는 것이 더 좋을 것입니다.
다시 말해서, 문장의 entity 정보들과 trigger를 연결시키면서 뽑아낼 수 있는 정보를 활용하면 event detection에서 ambiguity문제가 개선된 결과를 낼 수 있을 것이라 주장할 수 있을 것입니다.
그러므로 entity type들을 하나의 독립적인 정보로서 활용해보면 detector입장에서는 유의미한 정보가 될 수 있을 것이라고 할 수 있습니다.
(Liu 2017)Exploiting argument information to improve event detection via supervised attention mechanisms.
위 논문에서는 Event Detection에서 candidate trigger word에 대해 local contextual words와 local contextual entities의 attention vector를 추가 정보로 event detector에 넘겨주는 방식을 채택합니다.
본 논문에서 소개하는 방법론과의 차이점을 몇 가지 생각해봤을 때 우선 위 논문은 우선 local context를 고려하는 방식을 채택하여, context 정보를 제한적으로 바라보게 된다고 생각합니다.
그리고 위 논문은 대충 보면 sequential feature를 활용하는 것처럼 보일 수도 있을 것 같은데 저는 attention vector를 적당히 계산한 뒤 contextual matrix에 대해 weighted sum 연산을 진행하여 local context를 집계한 정보를 활용했다고 보았습니다.
또한 entity type에 NA를 포함시켜서 network를 진행시키는데, 뒤에도 나오지만 본 논문에서는 relation 연산에서 NA를 제외하는 처리를 포함시킵니다.
다른 논문들도 소개가 돼있는데 embedding 단에서의 entity 정보를 추가하는 수준으로 mixed representation을 학습하는 접근법들입니다.
추가적으로 knowledge distillation 같은 방법들도 같이 이용이 되긴 하는데, 본문에서는 깊게 다루지 않겠습니다.
저자들이 본 논문에서 주로 다루는 부분은 sentence information modeling입니다.
본문에도 적혀있듯이 문장의 의미적인 부분에 영향을 많이 주는 것이 단어의 순서(order of tokens)라고 생각했다고 합니다.
그래서 word sequence에서 sequential feature를 뽑아내는 것과 비슷하게, entity type sequence에서도 sequential feature를 뽑아내고 이용하고자 했습니다.
문장을 이루는 단어들의 entity type 순서가 Event Detection task에 중요한 부분이 될 것이라고 생각하고 접근했기 때문입니다.
이전까지의 연구들이 entity type sequence를 하나의 독립적인 sequence로 생각하면서 sequential feature를 뽑았던 시도를 하지 않았다는 것을 motivation으로 논문 작성을 전개한 것 같습니다.
본 논문에서는 entity type sequence와 word sequence를 모두 활용하는 Entity-Type-Enhanced-Event-Detection(ETEED)를 제안합니다.
ETEED는 word sequence와 entity type sequence의 가치를 동등하게 여겨 각 sequence의 representation을 독립적으로 학습합니다.
이때 각 sequential feature는 독립적인 Transformer Encoder로 뽑히게 됩니다.
그리고 trigger와 entity type들의 correlation을 학습하고자 trigger-entity interaction learning module을 제안합니다.
여기서 주목해야 할 점은, 전체 entity type sequence에 기반한 attention value를 계산하는 것이 아니라 entity mention's type와 candidate trigger의 relation을 계산하도록 합니다.
다시 말해서 NA type 같은 불필요한 entity type은 제외하고 entity mention만 활용하겠다는 것입니다.
contribution
1. entity type sequence의 sequential feature를 학습
2. entity mention과 candidate trigger의 관계를 학습하는 attention based trigger-entity-interaction learning module 제안
3. ACE2005 dataset에 대하여 이전 연구들에 비해 성능 향상
Approach
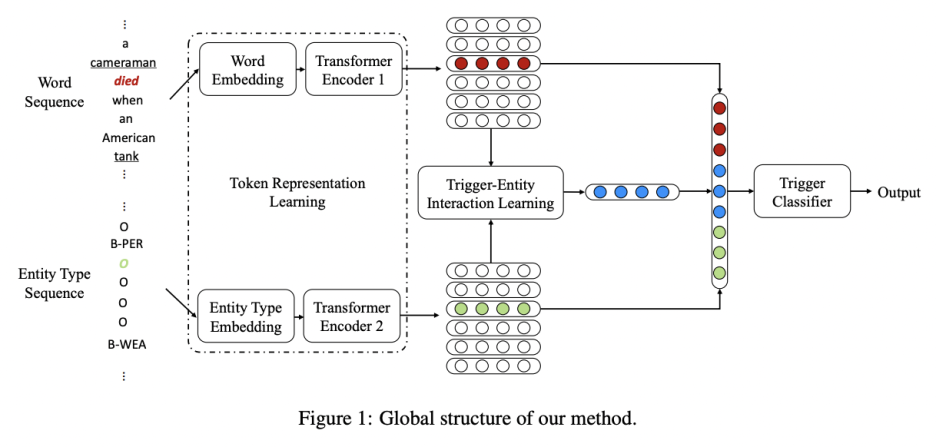
- token representation learning
- attention-based feature learning (trigger-entity interaction learning)
- trigger classfication
token representation learning
길이가 n인 sample에 대해서 word sequence와 entity type sequence를 다음과 같이 표기합니다.
$ w = \{w_1, w_2,..., w_n\} $ 여기서 $w_i$는 문장에서 $i$번째 단어를 의미합니다
$ e = \{e_1, e_2,..., e_n\} $는 $w$에 대응하는 entity type입니다.
또한, $c$는 sequence에서 candidate trigger의 위치를 나타내는 첨자로 사용합니다.
그래서 $w_c$와 $e_c$는 각각 candidate trigger의 word와 entity type입니다.
1. Embedding Layer
embedding layer를 통해 word token과 entity type token을 실수 벡터로 변환시킵니다.
word token에 대해서는 pre-trained embedding을 사용합니다. (실험에서는 Glove 사용)
이때 $w_i$에 대해 embedding vector는 $x_{w_i}$로 표기합니다.
entity type token에 대해서는 random initialization 하며 training동안 update 됩니다.
그리고 $e_i$에 대해 embedding vector는 $x_{e_i}$로 표기합니다.
2. Transformer Encoder
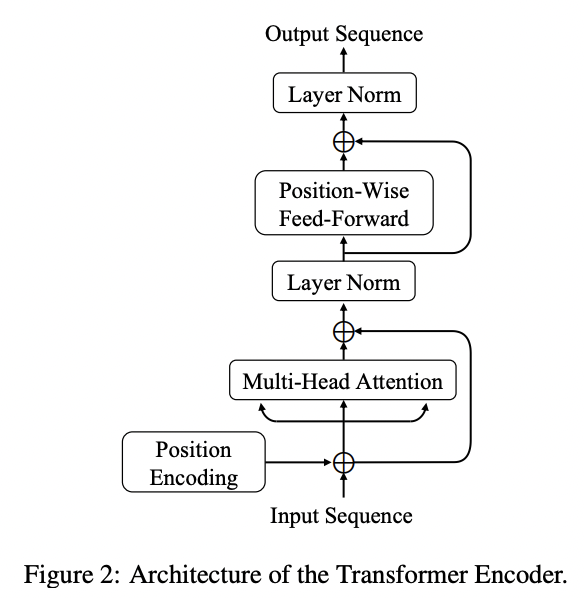
Transformer는 attention is all you need 논문에서 제안된 attention mechanism으로만 이뤄진 모델입니다.
최근 몇 년에 걸쳐서 자연어 처리 분야에 Transformer가 추세가 되어가고 있는데, 그 이유는 RNN류 모델들에 비해 장점이 많기 때문입니다.
우선 Transformer는 구조상 long term dependency에 비교적 자유로우며 병렬 연산이 가능한 모델입니다.
RNN류 모델들은 길이가 긴 문장을 처리할 때 time step이 진행됨에 따라 초기 정보가 점점 희석되는 문제점을 지니고 있지만
그에 비해 Transformer는 연산적으로 long term dependency에 자유롭다는 장점을 가집니다.
그리고 gradient vanishing이 방지된다는 장점 또한 가져갑니다.
long term dependency를 그나마 이론적으로 해결한 LSTMs는 RNN에 비해 연산에서 문장 길이를 길게 가져갈 수는 있지만
layer가 깊어졌을 때 생기는 gradient vanishing 문제는 해결하지 못했습니다.
반면 transformer는 연산 과정 중간마다 residual connection이 포함되어 있어서 gradient vanishing이 어느 정도 방지되고 있습니다.
그래서 layer를 깊게 가져갈 수 있다는 점으로부터 feature가 non linearity를 더 가져갈 수 있다는 장점도 있다고 생각합니다.
또한 attention is all you need 논문에서 모델의 연산속도가 빠르다는 장점이 있다는 것도 확인할 수 있습니다.
transformers가 추세가 되고 있는 만큼 단점들을 보완하기 위해 다양한 연구들이 진행되고 있는데,
우선 data hungry 모델이라는 단점이 있습니다.
이에 따라 최근 몇 년 동안 transformer에 기반한 pretrained language model(BERT, T5, GPT, ERNIE...)들이 여럿 나오고 있습니다.
다음으로는 입력 문장이 고정된 길이로만 들어올 수 있다는 단점이 존재합니다.
고정된 길이로 들어와야 해서 입력 문장의 길이가 예상보다 길어지면 문장을 잘라서 처리해야 하기 때문에 결과에 안 좋은 영향을 끼치게 됩니다.
이를 해결하고자 transformer-XL과 같은 연구들이 진행이 됐습니다.
그리고 연산량이 많다는 단점이 있습니다.
연산속도가 빠르다는 특징이 있었지만, multi head attention에서의 dot product연산은 계산 복잡도를 문장길이의 제곱만큼 가져가게 됩니다.
그래서 transformer의 경량화는 중요한 이슈로서 몇 년간 지속적으로 연구가 많이 진행되고 있습니다.
대표적으로 big bird, sparse transformer, linformer, combiner 등이 그런 시도라고 할 수 있습니다.
제가 아는 선에서는 아래와 같은 연구들이 주로 존재하는 것 같습니다.
1. 연산적인 트릭을 통한 경량화
2. matrix size를 정보 손실이 적은 방향으로 조절
3. key, value matrix에서 연산에 참여하는 부분들을 합리적으로 감소
아무튼 본 논문에서는 embedding layer에서 뽑힌 matrix를 transformer encoder에 넣어 sequential feature를 만들게 됩니다.
Event Detection은 language modeling까지 필요로 하는 task는 아니기 때문에 Decoder는 이용하지 않고
Encoder만 활용하여 sequence의 representation을 잘 추출할 수 있도록 합니다.
논문에서는 transformer의 구조에 대해서 구체적으로 설명하고 있는데, 제 포스팅에서는 다루지 않으려 합니다.
Transformer Encoder는 벡터 $\{x_1, x_2,..., x_n\} (x_i \in \mathbb {R}^d) $에 대해 $\{z_1, z_2,..., z_n\}$을 만들어 냅니다.
이때 $z_i \in \mathbb {R}^d$입니다.
위 notation에 따라서 Transformer Encoder는 $x_w$와 $x_e$에 대해 각각 $z_w = \{z_{w_1}, z_{w_2},..., z_{w_n}\}(z_{w_i}\in\mathbb {R}^{d_w})$ 와 $z_e = \{z_{e_1}, z_{e_2},..., z_{e_n}\}(z_{e_i}\in\mathbb {R}^{d_e})$을 만들어 냅니다.
Trigger-Entity Interaction Learning
Transformer Encoder를 통해 $z_w$와 $z_e$를 얻은 다음, candidate trigger와 entity type 간의 interaction을 인코딩합니다.
trigger-entity interaction learning module은 attention기반으로 이뤄져 있는데 candidate trigger와 entity type 간의 attention factor를 계산합니다.
그러나 entity type sequence는 대부분 type O(NA)로 구성되어 있습니다.
저자들은 type O를 그대로 두는 것이 entity mention's type과 candidate trigger 간의 관계를 모델링하는 데에 악영향을 끼칠 것이라고 생각했습니다.
그래서 Graph Convolutional Networks with Argument-Aware Pooling for Event Detection 논문에서 처럼 type O를 제외하고 relation을 연산하는 방식을 채택했습니다.
candidate trigger $z_{w_c}$와 entity type sequence $z_e$가 주어졌을 때, attention value는 다음과 같이 계산합니다.
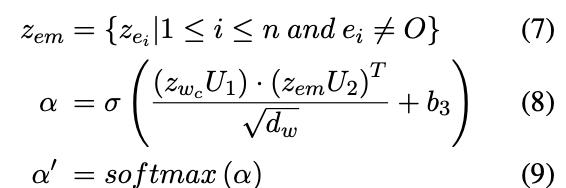
$where\;z_{em}\in\mathbb {R}^{k\times d_e}$,$U_1\in\mathbb {R}^{d_w\times d_w}$,$U_2\in\mathbb {R}^{d_e\times d_w}$,$b_3\in\mathbb {R}^k$
7번 수식에서 볼 수 있는 것처럼 $z_{em}$에는 $e_i$가 type O가 아닌 $z_{e_i}$가 모여있습니다.
attention is all you need에서 그랬듯 8번 수식에서 dot product 연산의 결과를 scaling 하려고 $\sqrt {d_w}$로 나누어줍니다.
여기서 candidate trigger의 수가 $t$개라고 하면 $z_{w_c} \in \mathbb {R}^{t\times d_w}$이고 $\alpha' \in \mathbb {R}^{t\times k}$입니다.
이때 $k$는 $z_{em}$에 속한 entity mention의 개수입니다.
결국 $\alpha'$은 candidate trigger에 대해서 entity mention 간의 관계를 나타내는 attention value라고 할 수 있을 것 같습니다.
마지막으로, trigger-entity interaction의 최종적인 벡터 표현을 연산하기 위해, $\alpha'$과 $z_{em}$의 dot product연산을 수행하게 됩니다.
이때 dot product연산 이전에 $z_{em}$에 relu activation function을 갖는 fully connected layer를 추가하여 model capability를 늘리고 $z_{em}$차원에 변화를 줍니다.
최종적인 interaction output은 다음과 같이 계산합니다
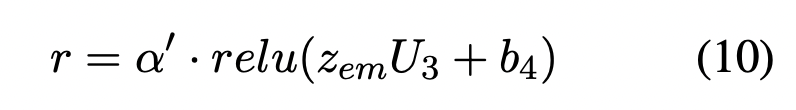
$where\;U_3 \in \mathbb {R}^{d_e \times d_w}, b_4 \in \mathbb {R}^{d_w}$
이때 $r \in \mathbb {R}^{t \times d_w}$은 trigger-entity interaction을 표현합니다.
Trigger Classification
최종적인 candidate trigger vector는 model figure에서 볼 수 있듯 trigger-entity interaction $r$과 candidate trigger $z_{w_c}$와 candidate trigger의 entity representation $z_{e_c}$를 concatenate 하여 표현합니다.
$\rightarrow [z_{w_c},z_{e_c},r] \in \mathbb {R}^{t \times (d_e+2d_w)}$
분류기로는 selu를 activation function으로 갖는 multi layer perceptron을 사용하여 , softmax function을 통해 candidate trigger가 각 event type들에 속할 confidence score를 계산합니다.
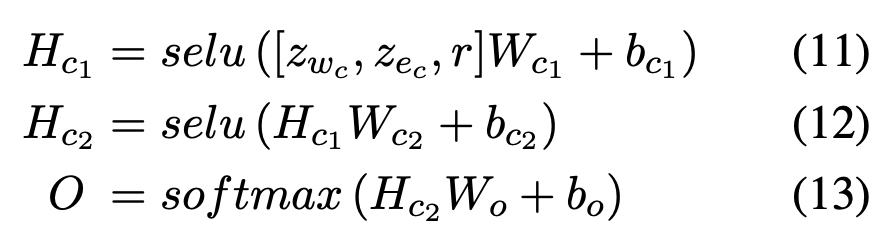
$where\;W_{c1} \in \mathbb {R}^{(d_e+2d_w) \times d_{c1}}, W_{c2} \in \mathbb {R}^{d_{c1} \times d_{c2}}, W_{o} \in \mathbb {R}^{d_{c2} \times d_{T}}$
$d_{T}$는 event type의 수를 의미합니다.
loss function으로는 cross entropy를 사용하고 training 동안 Adam optimizer를 통해 parameter들을 업데이트합니다.
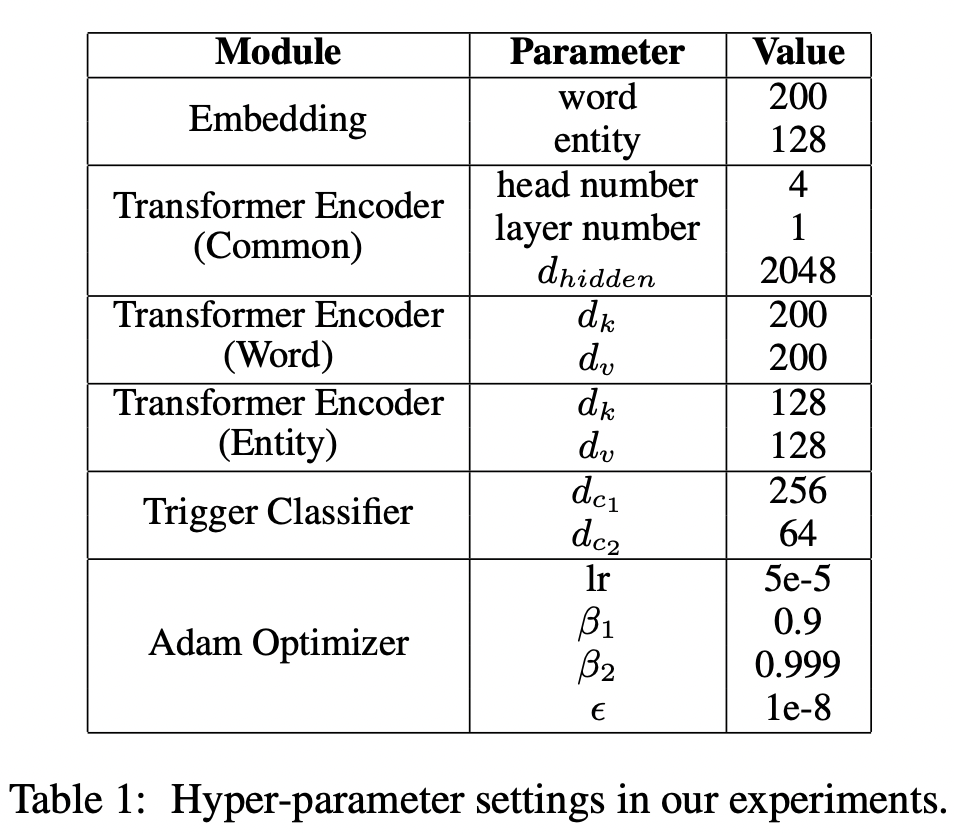
모든 parameter는 Xavier initialization으로 초기화합니다. 구체적인 hyper-parameter들은 다음 테이블과 같습니다.
Experiments
setting
- dataset : ACE 2005
event trigger가 분류될 33개의 event type이 존재하고, 실험에서는 NA까지 포함하여 총 34개의 type으로 분류 - entity type sequence를 만들때 BIO schema를 이용
training set 529 articles develop set 30 articles test set 40 articles - candidate trigger : noun, verb, adjective in sentences
- word token embedding : pretrained GloVe
entity types embedding : randomly initialization - metric : Precision, Recall, F1-score
performance
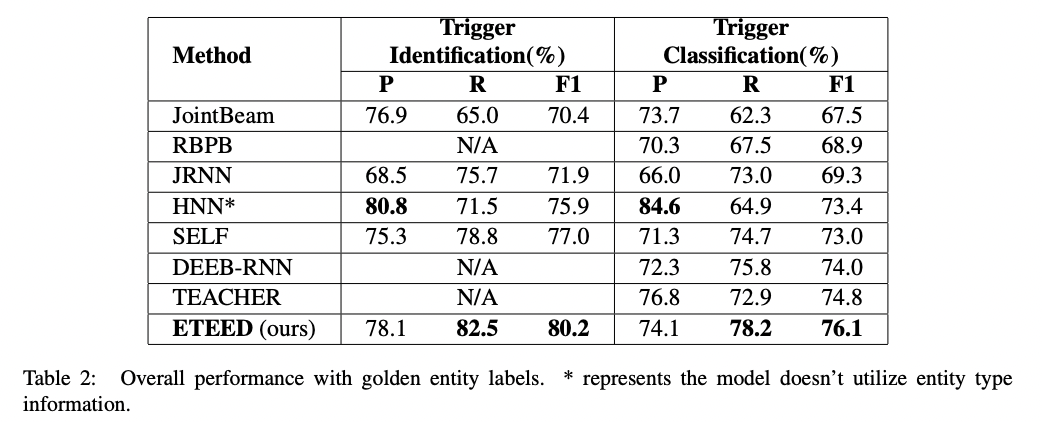
trigger identification과 trigger classification에 대해서 전반적으로 다른 approach보다 좋은 결과를 내고 있음을 볼 수 있습니다.
trigger identification
제안된 모델이 baseline model 중 상위 성능을 내고 있는 SELF에 비해 F1-score와 Recall이 각각 3.2%, 3.7%의 향상을 보이고 있으며 HNN에 비해서 precision은 낮은 결과를 보여주고 있지만 recall이 11% 더 높다는 것을 확인할 수 있습니다.
trigger classification
classification의 경우에서도 전반적으로 제안된 모델이 recall과 F1-score가 가장 높은 성능을 보이고 있습니다.
best baseline model인 TEACHER보다 F1-score에서 1.3%의 성능 향상을 보여주고 있으며, trigger identification과 비슷한 양상을 보여주고 있습니다.
classification(real scenario)
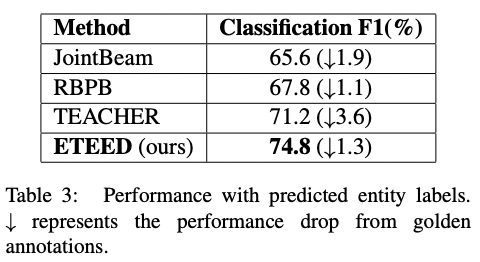
제안된 모델의 성능의 타당함을 보여주고자 저자들은 test time에 golden annotation뿐 아니라 예측된 entity type label을 이용하여 성능을 비교했습니다.
우선 BiLSTM-CRF 모델을 training set으로 학습시키고 test set에 대한 predicted entity type sequence를 얻어냅니다.
BiLSTM-CRF를 통해 얻은 test set에 대해서 실험을 진행하여 ETEED 모델을 baseline들과 비교하는데 표에서 볼 수 있듯이 제안된 모델이 가장 괜찮은 성능을 보여주고 있습니다.
그리고 golden annotation을 사용했을 때의 결과에 비해 비교적 적은 성능 하락(1.3% 낮아짐)을 보여주고 있습니다.
Effect of Entity Type Representation
entity type representation의 효과를 확인하고자, 저자들은 다음과 같이 추가적으로 실험을 진행했습니다.
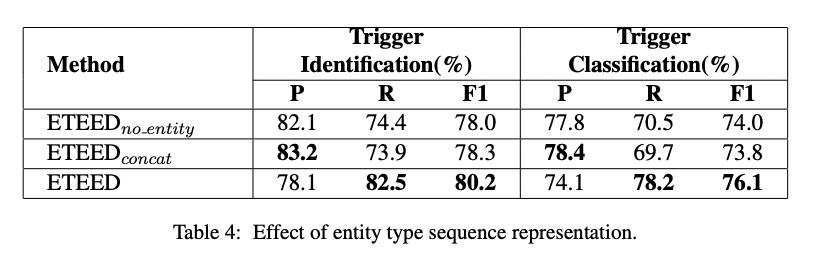
1. ETEED(no_entity)
word token sequence만 이용
2. ETEED(concat)
이전 연구에서 했던 것 처럼, model input으로 word sequence와 entity type representation을 concatenate를 진행하고 transformer encoder에 넣음
recall, F1-score측면에서 제안된 모델이 더 높은 성능을 보여주고 있습니다.
entity type sequential feature를 사용할 때 precision 측면에서는 약간의 손실이 있음을 볼 수 있지만 그에 비해 recall에 대해서는 significant 한 향상을 볼 수 있습니다.
(이하 실험 생략)
앞으로 제 주관적인 의견이 다소 포함된 nlp 논문 리뷰, 정리를 일주일에 한편씩은 포스팅하고자 노력할려고 합니다...
논문의 난이도가 높지는 않아서 편하고 재밌게 읽은 것 같습니다.
개인적으로 embedding을 학습하는 방향 대신 pretrained word embedding(GloVe)을 사용한 점과, interaction learning에서 dot product 연산이후에 sigmoid function이 포함된 점, 결과에 accuracy를 포함하지 않은 점이 의문이긴 합니다
embedding을 학습하는 방향을 채택하지 않은 이유는 데이터셋의 양이 적어서 그런 것 같긴 한데 혹시 의견 있으신 분 있으시다면 공유 부탁드리겠습니다.
그래도 전반적으로 논문이 읽기 편하게 쓰여져 있었고 entity sequential feature의 효과와 real scenario에 대한 실험 설계가 개인적으로 마음에 들었습니다.
지식 부족으로 잘못된 내용을 포스팅에 포함하거나, 생략할 수 있습니다.
보시는 분 있으시다면 피드백 부탁드립니다 감사합니다
'ai' 카테고리의 다른 글
| Attention is all you need (Transformer) (1) | 2023.11.20 |
|---|---|
| AR과 AE의 설명( in XL-Net ) (1) | 2023.11.20 |
| [메모용 | 2015 ICLR] Explaining and harnessing adversarial examples 전반부 (2) | 2023.11.20 |
| [arxiv-2021] VAE based Text Style Transfer with Pivot Words Enhancement Learning (0) | 2022.08.30 |